Many countries in the world allow access to a vast array of information, such as documents under freedom of information requests, statistics, datasets. In the European Union, most taxpayer financed data in government administration, transport, or meteorology, for example, can be usually re-used. More and more scientific output is expected to be reviewable and reproducible, which implies open access.
 |  |
 |  |
What’s the Problem with Open Data?
“Data is stuff. It is raw, unprocessed, possibly even untouched by human hands, unviewed by human eyes, un-thought-about by human minds.” [1]
- Most open data cannot be just “downloaded."
- Often, you need to put more than $100 value of work into processing, validating, documenting a dataset that is worth $100. But you can share this investment with our data observatories.
- Open data is almost always lacking of documentation, and no clear references to validate if the data is reliable or not corrupted. This is why we always start with reprocessing and redocumenting.
Read more: Open Data - The New Gold Without the Rush
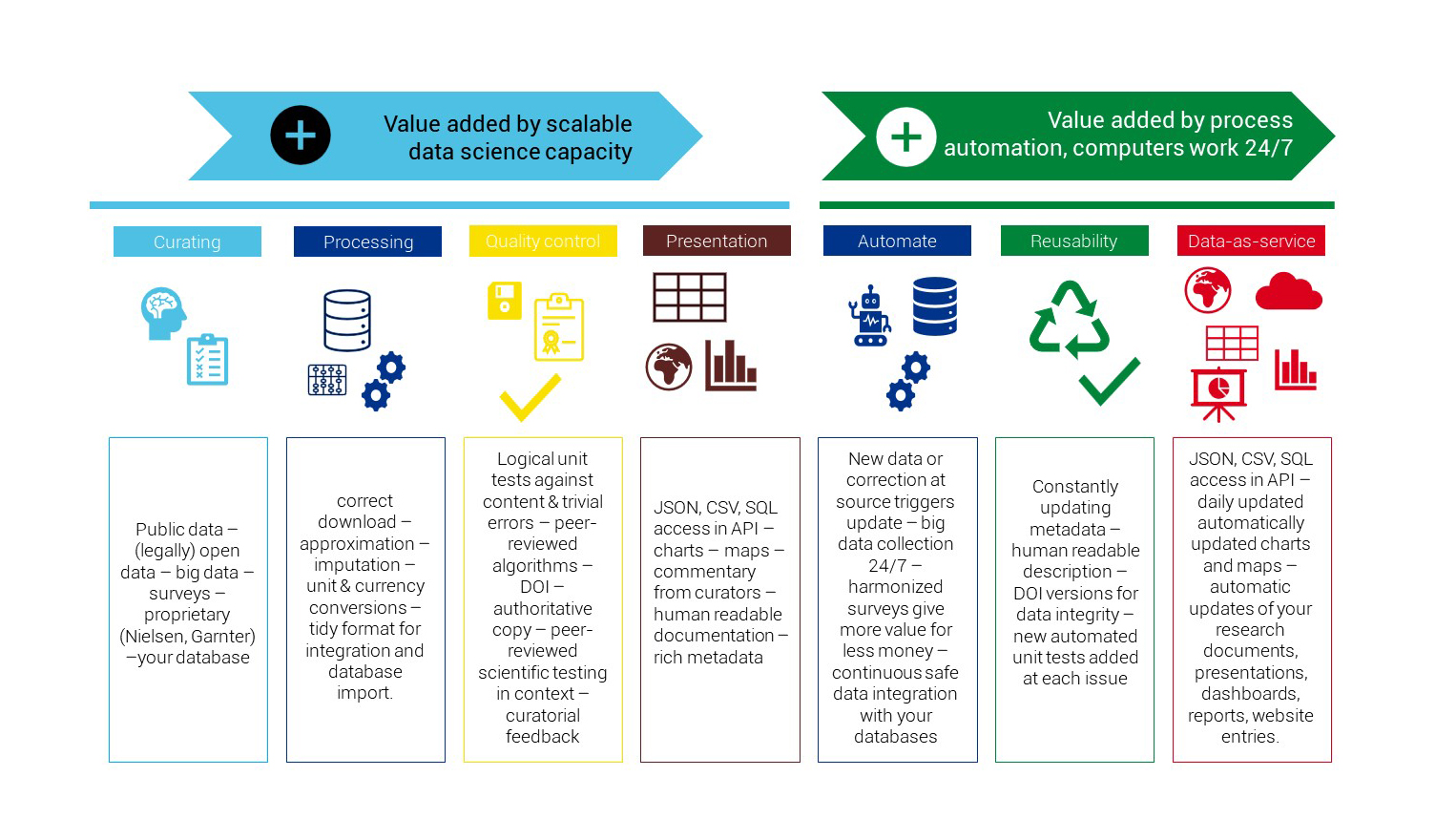
How We Add Value?
- We believe that even such generally trusted data sources as Eurostat often need to be reprocessed, because various legal and political constraints do not allow the common European statistical services to provide optimal quality data – for example, on the regional and city levels.
- With rOpenGov and other partners, we are creating open-source statistical software in R to re-process these heterogenous and low-quality data into tidy statistical indicators to automatically validate and document it.
- Metadata is a potentially informative data record about a potentially informative dataset. We are carefully documenting and releasing administrative, processing, and descriptive metadata, following international metadata standards, to make our data easy to find and easy to use for data analysts.
- We are automatically creating depositions and authoritative copies marked with an individual digital object identifier (DOI) to maintain data integrity.
Is There Value in Open Data?
A well-known story tells of a finance professor and a student who come across a $100 bill lying on the ground. As the student stops to pick it up, the professor says, “Don’t bother—if it were really a $100 bill, it wouldn’t be there.”
But this is not the case with open data. Often, you need to put more than $100 into processing, validating, documenting a dataset that is worth $100.
In the EU, open data is governed by the Directive on open data and the re-use of public sector information - in short: Open Data Directive (EU) 2019 / 1024. It entered into force on 16 July 2019. It replaces the Public Sector Information Directive, also known as the PSI Directive which dated from 2003 and was subsequently amended in 2013.
Open Data is potentially useful data that can potentially replace costlier or hard to get data sources to build information. It is analogous to potential energy: work is required to release it. We build automated systems that reduce this work and increase the likelihood that open data will offer the best value for money.
- Most open data is not publicy accessible, and available upon request. Our real curatorial advantage is that we know where it is and how to get this request processed.
- Most European open data comes from tax authorities, meteorological offices, managers of transport infrastructure, and other governmental bodies whose data needs are very different from yours. Their data must be carefully evaluated, re-processed, and if necessary, imputed to be usable for your scientific, business or policy goals.
- The use of open science data is problematic in different ways: usually understanding the data documentation requires domain-specific specialist knowledge. Open science data is even more scattered and difficult to access than technically open, but not public governmental data.
From Datasets to Data Integration, Data to Information
“Data is only potential information, raw and unprocessed, prior to anyone actually being informed by it.” ^[2]
- We are building simple databases and supporting APIs that release the data without restrictions, in a tidy format that is easy to join with other data, or easy to join into databases, together with standardized metadata.
FAQ
Why Downloading Does Not Work?
- Most open data is not available on the internet.
- If it is available, it is not in a form that you can easily import into a spreadsheet application like Excel or OpenOffice, or into a statistical application like SPSS or STATA.
- Even the data quality of trusted web sources, like the Eurostat website, can be very low. Eurostat just publishes what it gets from governments, and often has no mandate to fix errors. The data is full with missing information, and in the case of regional statistics, faulty region codes and region names that make matching your data or placing them on a map impossible.
- Adjusting euros with millions of euros, correctly translating dollars to euros, pounds to kilograms requires plenty of work. This is a very error-prone process when done by humans.
Can Open Data be Used in Machine Learning and AI?
- Most public and open data sources have many missing observations; machine learning models usually cannot hanlde missingness. These points must be carefully imputed with approximations, which can be very challenging when the data has geographical dimension.
- Removing missing values makes samples extremely biased and your model will learn from omissions, not information.
Photo Credits
What’s the Problem with Open Data? illustration is a photo by Cristina Gottardi How We Add Value? illustration is a photo by Nana Smirnova. Is There Value Left in It? is a photo by Imelda Datasets Should Work Together to Give Information is a photo by Lucas Santos
Footnote References
[1] Pomerantz, Jeffrey. 2021. “Metadata.” MIT Press essential knowledge series. MIT Press. Cambridge, Massachusetts ; London, England : The MIT Press, [2015]
[2] Pomerantz, Jeffrey. 2021. “Metadata.” MIT Press essential knowledge series. MIT Press. Cambridge, Massachusetts ; London, England : The MIT Press, [2015]
Daniel Antal
Data Scientist & Founder of the Digital Music Observatory
My research interests include reproducible social science, economics and finance.